Spoken Language Processing / Multimodal Interaction
Research in spoken language information processing, with a focus on speech recognition, and interaction using other modalities.
Speech is the most natural modality (means) of human communication. Our research aims to scientifically know, analyse and process speech, as well as to engineer the human ability to communicate.
Furthermore, we focus on applying this to the construction of future spoken dialogue and multimodal interaction systems.
Large Vocabulary Continuous Speech Recognition
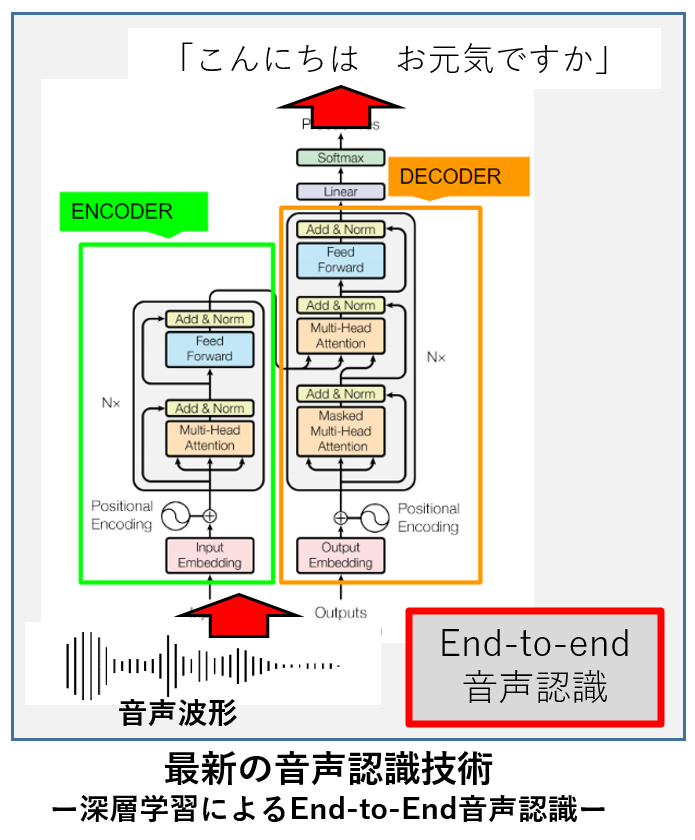
There are many situations where large-vocabulary continuous speech recognition is expected to be applied, for example, in the transcription of speech such as lecture speech.
In recent years, research into end-to-end speech recognition using deep learning models has progressed.
Various aspects, such as model improvement and methods for applying language models, are used to improve the accuracy of such models.
Elderly Voice Recognition
The so-called information-weak benefit from speech recognition and spoken dialogue.
It should be particularly useful for the elderly, who find it difficult to handle equipment due to unfamiliarity with information devices or reduced physical function.
However, research on speech recognition for the elderly has not progressed.
We are researching how to build a speech recognition system that can be used by the elderly, starting with a steady collection of elderly speech.
Spoken Dialogue Interfaces (1)
– Friendly Interaction –
How do ordinary users become familiar with spoken dialogue interfaces?
When they try it out, they find it hard to get a response, and they don’t know whether they are being heard or not, which is a barrier.
We are therefore trying to break down these barriers by creating a system that responds in real time, is attuned to the ‘excitement’ of the dialogue, and makes talking itself enjoyable.
We are also researching understanding methods that can robustly respond to all kinds of speech and quickly recover from confusion caused by misrecognition or misunderstanding.

Spoken Dialogue Interfaces (2)
– Application To The Field Of Medicine –
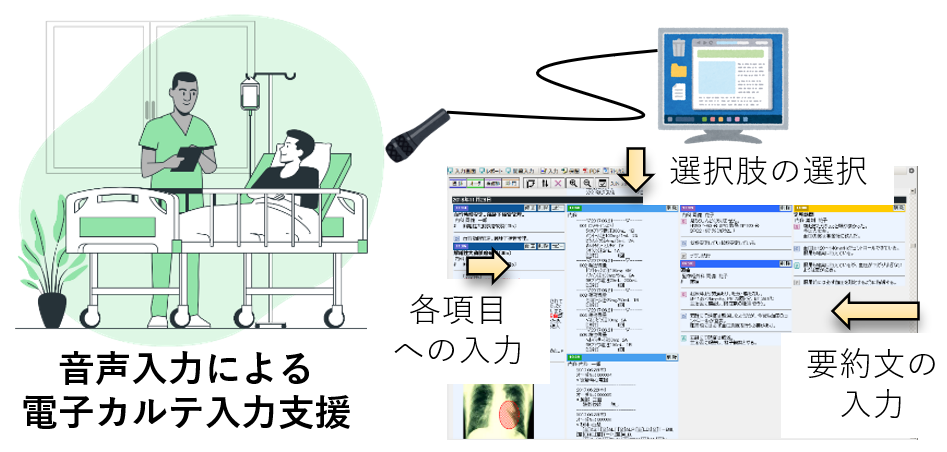
SmartHospital
Spoken Dialogue Interfaces (3)
– Interfaces That Work Naturally –
Multimodal Interface
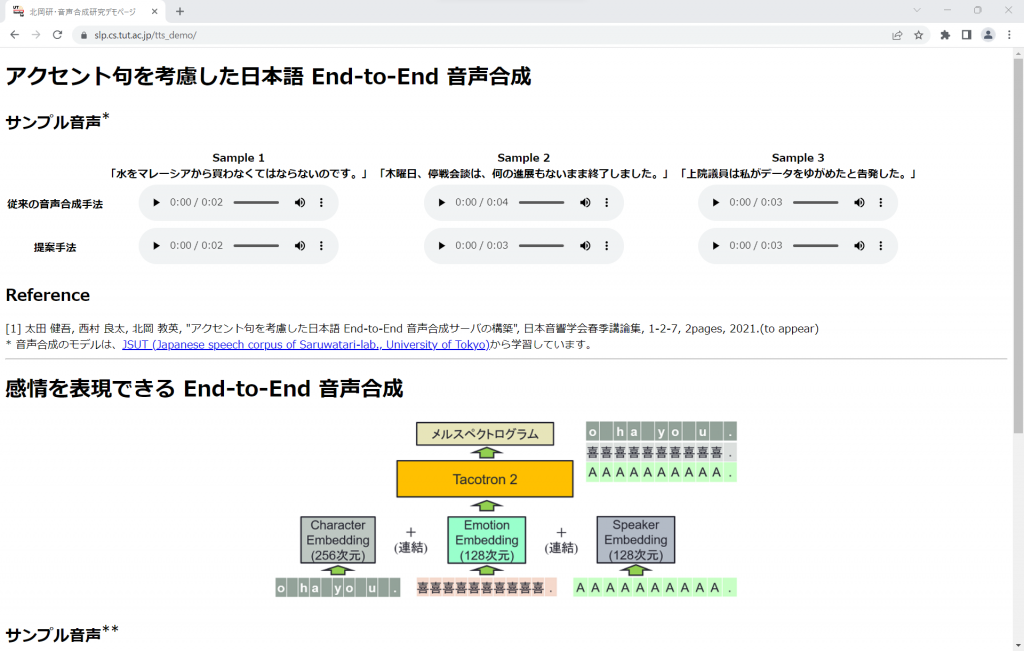
Natural And Expressive Speech Synthesis
Even if a variety of inputs are possible, a natural dialogue cannot be established if the system responds unnaturally.
It is desirable for speech synthesis to be of such high quality that it is indistinguishable from human speech, but also to be able to express individuality and emotions.
Therefore, we are aiming for natural and expressive speech synthesis by controlling prosody (voice intensity, such as accents, and high/low pitch) and learning emotional speech.
Teaching Materials prepared by Lab Students
This page introduces the teaching material “Actual Dialogue with ChatGPT” prepared by our lab students, Kumagai, Odom, and Oda.
This is a computer software “Spoken Dialogue System” that can interact with humans by voice using speech recognition, ChatGPT and speech synthesis.
Actual Dialogue with ChatGPT
More infomation, Click here.